![]()
Using Mixedbread.ai cross-encoder for reranking in Vespa.ai
First, let us recap what cross-encoders are and where they might fit in a Vespa application.
In contrast to bi-encoders, it is important to know that cross-encoders do NOT produce an embedding. Instead a cross-encoder acts on pairs of input sequences and produces a single scalar score between 0 and 1 indicating the similarity or relevance between the two sentences.
The cross-encoder model is a transformer based model with a classification head on top of the Transformer CLS token (classification token).
The model has been fine-tuned using the MS Marco passage training set and is a binary classifier which classifies if a query,document pair is relevant or not.
The quote is from this blog post from 2021 that explains cross-encoders more in depth. Note that the reference to the MS Marco dataset is for the model used in the blog post, and not the model we will use in this notebook.
Properties of cross-encoders and where they fit in Vespa
Cross-encoders are great at comparing a query and a document, but the time complexity increases linearly with the number of documents a query is compared to.
This is why cross-encoders are often part of solutions at the top of leaderboards for ranking performance, such as MS MARCO Passage Ranking leaderboard.
However, this leaderboard does not evaluate a solution’s latency, and for production systems, doing cross-encoder inference for all documents in a corpus become prohibitively expensive.
With Vespa’s phased ranking capabilites, doing cross-encoder inference for a subset of documents at a later stage in the ranking pipeline can be a good trade-off between ranking performance and latency. For the remainder of this notebook, we will look at using a cross-encoder in global-phase reranking, introduced in this blog post.
In this notebook, we will show how to use the Mixedbread.ai cross-encoder for global-phase reranking in Vespa.
The inference can also be run on GPU in Vespa Cloud, to accelerate inference even further.
Exploring the Mixedbread.ai cross-encoder
mixedbread.ai has done an amazing job of releasing both (binary) embedding-models and rerankers on huggingface 🤗 the last weeks.
Check out our previous notebook on using binary embeddings from mixedbread.ai in Vespa Cloud here
For this demo, we will use mixedbread-ai/mxbai-rerank-xsmall-v1, but you can experiment with the larger models, depending on how you want to balance speed, accuracy, and cost (if you want to use GPU).
This model is really powerful despite its small size, and provide a good trade-off between speed and accuracy.
Table of accuracy on a BEIR (11 datasets):
Model |
Accuracy |
|---|---|
Lexical Search |
66.4 |
bge-reranker-base |
66.9 |
bge-reranker-large |
70.6 |
cohere-embed-v3 |
70.9 |
mxbai-rerank-xsmall-v1 |
70.0 |
mxbai-rerank-base-v1 |
72.3 |
mxbai-rerank-large-v1 |
74.9 |
(Table from mixedbread.ai’s introductory blog post.)
As we can see, the mxbai-rerank-xsmall-v1 model is almost on par with much larger models, while being much faster and cheaper to run.
Downloading the model
We will use the quantized version of mxbai-rerank-xsmall-v1 for this demo, as it is faster and cheaper to run, but feel free to change to the model of your choice.
[1]:
import requests
from pathlib import Path
url = "https://huggingface.co/mixedbread-ai/mxbai-rerank-xsmall-v1/resolve/main/onnx/model_quantized.onnx"
local_model_path = "model/model_quantized.onnx"
r = requests.get(url)
# Create path if it doesn't exist
Path(local_model_path).parent.mkdir(parents=True, exist_ok=True)
with open(local_model_path, "wb") as f:
f.write(r.content)
print(f"Downloaded model to {local_model_path}")
Downloaded model to model/model_quantized.onnx
Inspecting the model
It is useful to inspect the expected inputs and outputs, along with their shapes, before integrating the model into Vespa.
This can either be done by for instance by using the sentence_transformers and onnxruntime libraries.
One-off tasks like this are well suited for a Colab notebook, one example on how to do this in colab can be found here:
![]()
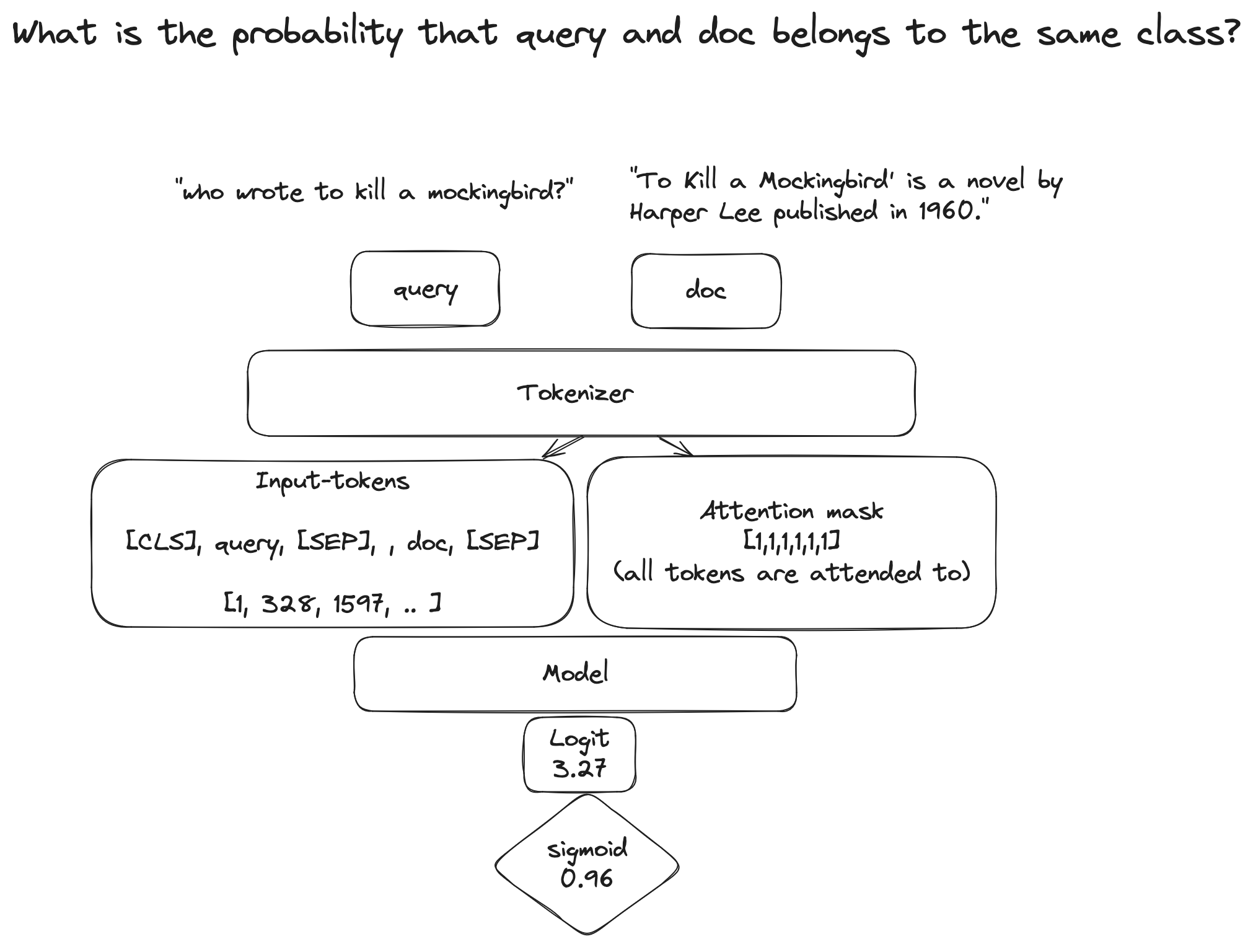
What does a crossencoder do?
Below, we have tried to visualize what is going on in a cross-encoder, which helps us understand how we can use it in Vespa.
We can see that the input pairs (query, document) are prefixed with a special [CLS] token, and separated by a [SEP] token.
In Vespa, we want to tokenize the document body at indexing time, and the query at query time, and then combine them in the same way as the cross-encoder does, during ranking.
Let us see how we can achieve this in Vespa.
Defining our Vespa application
[2]:
from vespa.package import (
Component,
Document,
Field,
FieldSet,
Function,
GlobalPhaseRanking,
OnnxModel,
Parameter,
RankProfile,
Schema,
)
schema = Schema(
name="doc",
mode="index",
document=Document(
fields=[
Field(name="id", type="string", indexing=["summary", "attribute"]),
Field(
name="text",
type="string",
indexing=["index", "summary"],
index="enable-bm25",
),
# Let´s add a synthetic field (see https://docs.vespa.ai/en/schemas.html#field)
# to define how the tokens are derived from the text field
Field(
name="body_tokens",
type="tensor<float>(d0[512])",
# The tokenizer will be defined in the next cell
indexing=["input text", "embed tokenizer", "attribute", "summary"],
is_document_field=False, # Indicates a synthetic field
),
],
),
fieldsets=[FieldSet(name="default", fields=["text"])],
models=[
OnnxModel(
model_name="crossencoder",
model_file_path=f"{local_model_path}",
inputs={
"input_ids": "input_ids",
"attention_mask": "attention_mask",
},
outputs={"logits": "logits"},
)
],
rank_profiles=[
RankProfile(name="bm25", first_phase="bm25(text)"),
RankProfile(
name="reranking",
inherits="default",
# We truncate the query to 64 tokens, meaning we have 512-64=448 tokens left for the document.
inputs=[("query(q)", "tensor<float>(d0[64])")],
# See https://huggingface.co/mixedbread-ai/mxbai-rerank-xsmall-v1/blob/main/tokenizer_config.json
functions=[
Function(
name="input_ids",
# See https://docs.vespa.ai/en/cross-encoders.html#roberta-based-model and https://docs.vespa.ai/en/reference/rank-features.html
expression="customTokenInputIds(1, 2, 512, query(q), attribute(body_tokens))",
),
Function(
name="attention_mask",
expression="tokenAttentionMask(512, query(q), attribute(body_tokens))",
),
],
first_phase="bm25(text)",
global_phase=GlobalPhaseRanking(
rerank_count=10,
# We use the sigmoid function to force the output to be between 0 and 1, converting logits to probabilities.
expression="sigmoid(onnx(crossencoder).logits{d0:0,d1:0})",
),
summary_features=[
"query(q)",
"input_ids",
"attention_mask",
"onnx(crossencoder).logits",
],
),
],
)
[3]:
from vespa.package import ApplicationPackage
app_package = ApplicationPackage(
name="reranking",
schema=[schema],
components=[
Component(
# See https://docs.vespa.ai/en/reference/embedding-reference.html#huggingface-tokenizer-embedder
id="tokenizer",
type="hugging-face-tokenizer",
parameters=[
Parameter(
"model",
{
"url": "https://huggingface.co/mixedbread-ai/mxbai-rerank-xsmall-v1/raw/main/tokenizer.json"
},
),
],
)
],
)
It is useful to inspect the schema-file (see https://docs.vespa.ai/en/reference/schema-reference.html) before deploying the application.
[4]:
print(schema.schema_to_text)
schema doc {
document doc {
field id type string {
indexing: summary | attribute
}
field text type string {
indexing: index | summary
index: enable-bm25
}
}
field body_tokens type tensor<float>(d0[512]) {
indexing: input text | embed tokenizer | attribute | summary
}
fieldset default {
fields: text
}
onnx-model crossencoder {
file: files/crossencoder.onnx
input input_ids: input_ids
input attention_mask: attention_mask
output logits: logits
}
rank-profile bm25 {
first-phase {
expression {
bm25(text)
}
}
}
rank-profile reranking inherits default {
inputs {
query(q) tensor<float>(d0[64])
}
function input_ids() {
expression {
customTokenInputIds(1, 2, 512, query(q), attribute(body_tokens))
}
}
function attention_mask() {
expression {
tokenAttentionMask(512, query(q), attribute(body_tokens))
}
}
first-phase {
expression {
bm25(text)
}
}
global-phase {
rerank-count: 10
expression {
sigmoid(onnx(crossencoder).logits{d0:0,d1:0})
}
}
summary-features {
query(q)
input_ids
attention_mask
onnx(crossencoder).logits
}
}
}
It looks fine. Now, let’s just save the application package first, so that we also have more insight into the other files that are part of the application package.
[5]:
# Optionally, we can also write the application package to disk before deploying it.
app_package.to_files("crossencoder-demo")
[6]:
from vespa.deployment import VespaDocker
vespa_docker = VespaDocker(port=8080)
vespa_docker.deploy(application_package=app_package)
Waiting for configuration server, 0/300 seconds...
Waiting for configuration server, 5/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Waiting for application status, 0/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Waiting for application status, 5/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Waiting for application status, 10/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Waiting for application status, 15/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Waiting for application status, 20/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Waiting for application status, 25/300 seconds...
Using plain http against endpoint http://localhost:8080/ApplicationStatus
Application is up!
Finished deployment.
[6]:
Vespa(http://localhost, 8080)
[7]:
from docker.models.containers import Container
def download_and_analyze_model(url: str, container: Container) -> None:
"""
Downloads an ONNX model from a specified URL and analyzes it within a Docker container.
Parameters:
url (str): The URL from where the ONNX model should be downloaded.
container (Container): The Docker container in which the command will be executed.
Raises:
Exception: Raises an exception if the command execution fails or if there are issues in streaming the output.
Note:
This function assumes that 'curl' and 'vespa-analyze-onnx-model' are available in the container environment.
"""
# Define the path inside the container where the model will be stored.
model_path = "/opt/vespa/var/model.onnx"
# Construct the command to download and analyze the model inside the container.
command = f"bash -c 'curl -Lo {model_path} {url} && vespa-analyze-onnx-model {model_path}'"
# Execute the command in the container and handle potential errors.
try:
exit_code, output = container.exec_run(command, stream=True)
# Print the output from the command.
for line in output:
print(line.decode(), end="")
except Exception as e:
print(f"An error occurred: {e}")
raise
url = "https://huggingface.co/mixedbread-ai/mxbai-rerank-xsmall-v1/resolve/main/onnx/model.onnx"
# Example usage:
download_and_analyze_model(url, vespa_docker.container)
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1120 100 1120 0 0 6054 0 --:--:-- --:--:-- --:--:-- 6054
100 271M 100 271M 0 0 26.7M 0 0:00:10 0:00:10 --:--:-- 27.0M
unspecified option[0](optimize model), fallback: true
vm_size: 167420 kB, vm_rss: 47032 kB, malloc_peak: 0 kb, malloc_curr: 1060 (before loading model)
vm_size: 525104 kB, vm_rss: 413188 kB, malloc_peak: 0 kb, malloc_curr: 358744 (after loading model)
model meta-data:
input[0]: 'input_ids' long[batch_size][sequence_length]
input[1]: 'attention_mask' long[batch_size][sequence_length]
output[0]: 'logits' float[batch_size][1]
unspecified option[1](symbolic size 'batch_size'), fallback: 1
unspecified option[2](symbolic size 'sequence_length'), fallback: 1
1713519978.318630 localhost 1145/43932 - .eval.onnx_wrapper warning input 'input_ids' with element type 'long' is bound to vespa value with cell type 'double'; adding explicit conversion step (this conversion might be lossy)
1713519978.318646 localhost 1145/43932 - .eval.onnx_wrapper warning input 'attention_mask' with element type 'long' is bound to vespa value with cell type 'double'; adding explicit conversion step (this conversion might be lossy)
test setup:
input[0]: tensor(d0[1],d1[1]) -> long[1][1]
input[1]: tensor(d0[1],d1[1]) -> long[1][1]
output[0]: float[1][1] -> tensor<float>(d0[1],d1[1])
unspecified option[3](max concurrent evaluations), fallback: 1
vm_size: 525104 kB, vm_rss: 413316 kB, malloc_peak: 0 kb, malloc_curr: 358744 (no evaluations yet)
vm_size: 525104 kB, vm_rss: 413576 kB, malloc_peak: 0 kb, malloc_curr: 358744 (concurrent evaluations: 1)
estimated model evaluation time: 3.70174 ms
By doing this with the different size models and their quantized versions, we get this table.
Model |
Model File |
Inference Time (ms) |
Size |
N docs in 200ms |
|---|---|---|---|---|
mixedbread-ai/mxbai-rerank-xsmall-v1 |
model_quantized.onnx |
2.4 |
87MB |
82 |
mixedbread-ai/mxbai-rerank-xsmall-v1 |
model.onnx |
3.8 |
284MB |
52 |
mixedbread-ai/mxbai-rerank-base-v1 |
model_quantized.onnx |
5.4 |
244MB |
37 |
mixedbread-ai/mxbai-rerank-base-v1 |
model.onnx |
10.3 |
739MB |
19 |
mixedbread-ai/mxbai-rerank-large-v1 |
model_quantized.onnx |
16.0 |
643MB |
12 |
mixedbread-ai/mxbai-rerank-large-v1 |
model.onnx |
35.6 |
1.74GB |
5 |
With a time budget of 200ms for reranking, we can add a column indicating the number of documents we are able to rerank within the budget time.
[8]:
from vespa.application import Vespa
app = Vespa(url="http://localhost", port=8080)
[9]:
# Feed a few sample documents to the application
sample_docs = [
{"id": i, "fields": {"text": text}}
for i, text in enumerate(
[
"'To Kill a Mockingbird' is a novel by Harper Lee published in 1960. It was immediately successful, winning the Pulitzer Prize, and has become a classic of modern American literature.",
"The novel 'Moby-Dick' was written by Herman Melville and first published in 1851. It is considered a masterpiece of American literature and deals with complex themes of obsession, revenge, and the conflict between good and evil.",
"Harper Lee, an American novelist widely known for her novel 'To Kill a Mockingbird', was born in 1926 in Monroeville, Alabama. She received the Pulitzer Prize for Fiction in 1961.",
"Jane Austen was an English novelist known primarily for her six major novels, which interpret, critique and comment upon the British landed gentry at the end of the 18th century.",
"The 'Harry Potter' series, which consists of seven fantasy novels written by British author J.K. Rowling, is among the most popular and critically acclaimed books of the modern era.",
"'The Great Gatsby', a novel written by American author F. Scott Fitzgerald, was published in 1925. The story is set in the Jazz Age and follows the life of millionaire Jay Gatsby and his pursuit of Daisy Buchanan.",
]
)
]
[10]:
from vespa.io import VespaResponse
def callback(response: VespaResponse, id: str):
if not response.is_successful():
print(
f"Failed to feed document {id} with status code {response.status_code}: Reason {response.get_json()}"
)
app.feed_iterable(sample_docs, schema="doc", callback=callback)
[11]:
from pprint import pprint
with app.syncio(connections=1) as sync_app:
query = sync_app.query(
body={
"yql": "select * from sources * where userQuery();",
"query": "who wrote to kill a mockingbird?",
"input.query(q)": "embed(tokenizer, @query)",
"ranking.profile": "reranking",
"ranking.listFeatures": "true",
"presentation.timing": "true",
}
)
for hit in query.hits:
pprint(hit["fields"]["text"])
pprint(hit["relevance"])
("'To Kill a Mockingbird' is a novel by Harper Lee published in 1960. It was "
'immediately successful, winning the Pulitzer Prize, and has become a classic '
'of modern American literature.')
0.9634037778787636
("Harper Lee, an American novelist widely known for her novel 'To Kill a "
"Mockingbird', was born in 1926 in Monroeville, Alabama. She received the "
'Pulitzer Prize for Fiction in 1961.')
0.8672221280618897
("'The Great Gatsby', a novel written by American author F. Scott Fitzgerald, "
'was published in 1925. The story is set in the Jazz Age and follows the life '
'of millionaire Jay Gatsby and his pursuit of Daisy Buchanan.')
0.09325768904619067
("The novel 'Moby-Dick' was written by Herman Melville and first published in "
'1851. It is considered a masterpiece of American literature and deals with '
'complex themes of obsession, revenge, and the conflict between good and '
'evil.')
0.010269765303083865
It will of course be necessary to evaluate the performance of the cross-encoder in your specific use-case, but this notebook should give you a good starting point.
Next steps
Try to use hybrid search for the first phase, and rerank with a cross-encoder.
Cleanup
[12]:
vespa_docker.container.stop()
vespa_docker.container.remove()