![]()
Using Cohere Binary Embeddings in Vespa
Cohere just released a new embedding API supporting binary and int8 vectors. Read the announcement in the blog post: Cohere int8 & binary Embeddings - Scale Your Vector Database to Large Datasets.
We are excited to announce that Cohere Embed is the first embedding model that natively supports int8 and binary embeddings.
This is significant because:
Binarization reduces the storage footprint from 1024 floats (4096 bytes) per vector to 128 int8 (128 bytes).
32x less data to store
Faster distance calculations using hamming distance, which Vespa natively supports for bits packed into int8 precision. More on hamming distance in Vespa.
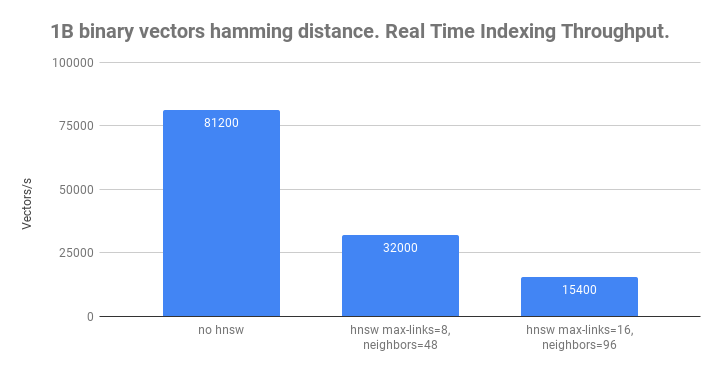
Vespa supports hamming distance with and without hnsw indexing.
For those wanting to learn more about binary vectors, we recommend our 2021 blog series on Billion-scale vector search with Vespa and Billion-scale vector search with Vespa - part two.
This notebook demonstrates how to use the Cohere binary vectors with Vespa, including a re-ranking phase that uses the float query vector version for improved accuracy. From the Cohere blog announcement:
To improve the search quality, the float query embedding can be compared with the binary document embeddings using dot-product. So we first retrieve 10*top_k results with the binary query embedding, and then rescore the binary document embeddings with the float query embedding. This pushes the search quality from 90% to 95%.
Install the dependencies:
[ ]:
!pip3 install -U pyvespa cohere==4.57
Examining the Cohere embeddings
Let us check out the Cohere embedding API and how we can obtain binarized embeddings. See also the Cohere embed API doc.
[2]:
import cohere
# Make sure that the environment variable CO_API_KEY is set to your API key
co = cohere.Client()
Some sample documents
Define a few sample documents that we want to embed
[3]:
documents = [
"Alan Turing was an English mathematician, computer scientist, logician, cryptanalyst, philosopher and theoretical biologist.",
"Albert Einstein was a German-born theoretical physicist who is widely held to be one of the greatest and most influential scientists of all time.",
"Isaac Newton was an English polymath active as a mathematician, physicist, astronomer, alchemist, theologian, and author who was described in his time as a natural philosopher.",
"Marie Curie was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity",
]
Notice that we ask for embedding_types=["binary]
[4]:
# Compute the binary embeddings ofdocuments.
# Set input_type to "search_document" and embedding_types to "binary"
cohere_response = co.embed(
documents,
model="embed-english-v3.0",
input_type="search_document",
embedding_types=["binary"],
)
[5]:
print(cohere_response.embeddings.binary)
[[-110, 121, 110, -50, 87, -59, 8, 35, 114, 30, -92, -112, -118, -16, 7, 96, 17, 51, 97, -9, -23, 25, -103, -35, -78, -47, 64, -123, -41, 67, 14, -31, -42, -126, 75, 111, 62, -64, 57, 64, -52, -66, -64, -12, 100, 99, 87, 61, -5, 5, 23, 34, -75, -66, -16, 91, 92, 121, 55, 117, 100, -112, -24, 84, 84, -65, 61, -31, -45, 7, 44, 8, -35, -125, 16, -50, -52, 11, -105, -32, 102, -62, -3, 86, -107, 21, 95, 15, 27, -79, -20, 114, 90, 125, 110, -97, -15, -98, 21, -102, -124, 112, -115, 26, -86, -55, 67, 7, 11, -127, 125, 103, -46, -55, 79, -31, 126, -32, 33, -128, -124, -80, 21, 27, -49, -9, 112, 101], [-110, -7, -24, 23, -33, 68, 24, 35, 22, -50, -32, 86, 74, -14, 71, 96, 81, -45, 105, -25, -73, 108, -99, 13, -76, 125, 73, -44, -34, -34, -105, 75, 86, -58, 85, -30, -92, -27, -39, 0, -75, -2, 30, -12, -116, 9, 81, 39, 76, 44, 87, 20, -43, 110, -75, 20, 108, 125, -75, 85, -28, -118, -24, 127, 78, -75, 108, -20, -48, 3, 12, 12, 71, -29, -98, -26, 68, 11, 0, -104, 96, 70, -3, 53, -98, -108, 127, -102, -17, -84, -88, 88, -54, -45, -11, -4, -4, 15, -67, 122, -108, 117, -51, 40, 98, -47, 102, -103, 3, -123, -85, 119, -48, -24, 95, -34, -26, -24, -31, -9, 99, 64, -128, -43, 74, -91, 80, -95], [64, -14, -4, 30, 118, 5, 8, 35, 51, 3, 72, -122, -70, -10, 2, -20, 17, 115, -67, -9, 115, 31, -103, -73, -78, 65, 64, -123, -41, 91, 14, -39, -41, -78, 73, -62, 60, -28, 89, 32, 33, -35, -62, 116, 102, -45, 83, 63, 73, 37, 23, 64, -43, -46, -106, 83, 109, 92, -87, -15, -60, -39, -23, 63, 84, 56, -6, -15, 20, 3, 76, 3, 104, -16, -79, 70, -123, 15, -125, -111, 109, -105, -99, 82, -19, -27, 95, -113, 94, -74, 57, 82, -102, -7, -95, -21, -3, -66, 73, 95, -124, 37, -115, -81, 107, -55, -25, 6, 19, -107, -120, 111, -110, -23, 79, -26, 106, -61, -96, -77, 9, 116, -115, -67, -63, -9, -43, 77], [-109, -7, -32, 19, 87, 116, 8, 35, 54, -102, -64, -106, -14, -10, 31, 78, -99, 59, -6, -45, 97, 96, -103, 37, 69, -35, -119, -59, 95, 27, 14, 73, 86, -9, -43, 110, -70, 96, 45, 32, -91, 62, -64, -12, 100, -55, 34, 62, 14, 5, 22, 67, -75, -17, -14, 81, 45, 125, -15, -11, -28, 75, -25, 20, 42, -78, -4, -67, -44, 11, 76, 3, 127, 40, 0, 103, 75, -62, -123, -111, 64, -13, -10, -5, -66, -89, 119, -70, -29, -95, -19, 82, 106, 127, -24, -11, -48, 15, -29, -102, -115, 107, -115, 55, -69, -61, 103, 11, 3, 25, -118, 63, -108, 11, 78, -28, 14, 124, 119, -61, 97, 84, 53, 69, 123, 89, -104, -127]]
As we can see from the above, we got an array of binary embeddings, using signed int8 precision in the numeric range [-128 to 127]. Each embedding vector has 128 dimensions:
[6]:
len(cohere_response.embeddings.binary[0])
[6]:
128
Definining the Vespa application
First, we define a Vespa schema with the fields we want to store and their type.
Notice the binary_vector field that defines an indexed (dense) Vespa tensor with the dimension name x[128]. Indexing specifies index which means that Vespa will use HNSW indexing for this field. Also notice the configuration of distance-metric where we specify hamming.
[20]:
from vespa.package import Schema, Document, Field, FieldSet
my_schema = Schema(
name="doc",
mode="index",
document=Document(
fields=[
Field(
name="doc_id",
type="string",
indexing=["summary", "index"],
match=["word"],
rank="filter",
),
Field(
name="text",
type="string",
indexing=["summary", "index"],
index="enable-bm25",
),
Field(
name="binary_vector",
type="tensor<int8>(x[128])",
indexing=["attribute", "index"],
attribute=["distance-metric: hamming"],
),
]
),
fieldsets=[FieldSet(name="default", fields=["text"])],
)
We must add the schema to a Vespa application package. This consists of configuration files, schemas, models, and possibly even custom code (plugins).
[21]:
from vespa.package import ApplicationPackage
vespa_app_name = "cohere"
vespa_application_package = ApplicationPackage(name=vespa_app_name, schema=[my_schema])
In the last step, we configure ranking by adding rank-profile’s to the schema.
unpack_bits unpacks the binary representation into a 1024-dimensional float vector doc.
We define two tensor inputs, one compact binary representation that is used for the nearestNeighbor search and one full version that is used in ranking.
[22]:
from vespa.package import RankProfile, FirstPhaseRanking, SecondPhaseRanking, Function
rerank = RankProfile(
name="rerank",
inputs=[
("query(q_binary)", "tensor<int8>(x[128])"),
("query(q_full)", "tensor<float>(x[1024])"),
],
functions=[
Function( # this returns a tensor<float>(x[1024]) with values -1 or 1
name="unpack_binary_representation",
expression="2*unpack_bits(attribute(binary_vector)) -1",
)
],
first_phase=FirstPhaseRanking(
expression="closeness(field, binary_vector)" # 1/(1 + hamming_distance). Calculated between the binary query and the binary_vector
),
second_phase=SecondPhaseRanking(
expression="sum( query(q_full)* unpack_binary_representation )", # re-rank using the dot product between float query and the unpacked binary representation
rerank_count=100,
),
match_features=[
"distance(field, binary_vector)",
"closeness(field, binary_vector)",
],
)
my_schema.add_rank_profile(rerank)
Deploy the application to Vespa Cloud
With the configured application, we can deploy it to Vespa Cloud. It is also possible to deploy the app using docker; see the Hybrid Search - Quickstart guide for an example of deploying it to a local docker container.
Install the Vespa CLI using homebrew - or download a binary from GitHub as demonstrated below.
[ ]:
!brew install vespa-cli
Alternatively, if running in Colab, download the Vespa CLI:
[ ]:
import os
import requests
res = requests.get(
url="https://api.github.com/repos/vespa-engine/vespa/releases/latest"
).json()
os.environ["VERSION"] = res["tag_name"].replace("v", "")
!curl -fsSL https://github.com/vespa-engine/vespa/releases/download/v${VERSION}/vespa-cli_${VERSION}_linux_amd64.tar.gz | tar -zxf -
!ln -sf /content/vespa-cli_${VERSION}_linux_amd64/bin/vespa /bin/vespa
To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:
Create a tenant at console.vespa-cloud.com (unless you already have one). This step requires a Google or GitHub account, and will start your free trial. Make note of the tenant name, it is used in the next steps.
Configure Vespa Cloud date-plane security
Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See Vespa Cloud Security Guide for details.
We save the paths to the credentials for later data-plane access without using pyvespa APIs.
[ ]:
import os
os.environ["TENANT_NAME"] = "vespa-team" # Replace with your tenant name
vespa_cli_command = (
f'vespa config set application {os.environ["TENANT_NAME"]}.{vespa_app_name}'
)
!vespa config set target cloud
!{vespa_cli_command}
!vespa auth cert -N
Validate that we have the expected data-plane credential files:
[24]:
from os.path import exists
from pathlib import Path
cert_path = (
Path.home()
/ ".vespa"
/ f"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem"
)
key_path = (
Path.home()
/ ".vespa"
/ f"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem"
)
if not exists(cert_path) or not exists(key_path):
print(
"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error"
)
Note that the subsequent Vespa Cloud deploy call below will add data-plane-public-cert.pem to the application before deploying it to Vespa Cloud, so that you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.
Configure Vespa Cloud control-plane security
Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.
The generated tenant api key must be added in the Vespa Console before attemting to deploy the application.
To use this key in Vespa Cloud click 'Add custom key' at
https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys
and paste the entire public key including the BEGIN and END lines.
[ ]:
!vespa auth api-key
from pathlib import Path
api_key_path = Path.home() / ".vespa" / f"{os.environ['TENANT_NAME']}.api-key.pem"
Deploy to Vespa Cloud
Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!
PyVespa supports deploying apps to the development zone.
Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.
[26]:
from vespa.deployment import VespaCloud
def read_secret():
"""Read the API key from the environment variable. This is
only used for CI/CD purposes."""
t = os.getenv("VESPA_TEAM_API_KEY")
if t:
return t.replace(r"\n", "\n")
else:
return t
vespa_cloud = VespaCloud(
tenant=os.environ["TENANT_NAME"],
application=vespa_app_name,
key_content=read_secret() if read_secret() else None,
key_location=api_key_path,
application_package=vespa_application_package,
)
Now deploy the app to Vespa Cloud dev zone.
The first deployment typically takes 2 minutes until the endpoint is up.
[ ]:
from vespa.application import Vespa
app: Vespa = vespa_cloud.deploy()
Feed our sample documents and their binary embedding representation
With few documents, we use the synchronous API. Read more in reads and writes.
[28]:
from vespa.io import VespaResponse
with app.syncio(connections=12) as sync:
for i, doc in enumerate(documents):
response: VespaResponse = sync.feed_data_point(
schema="doc",
data_id=str(i),
fields={
"doc_id": str(i),
"text": doc,
"binary_vector": cohere_response.embeddings.binary[i],
},
)
assert response.is_successful()
For some cases where we have lots of vector data, we can use the hex format for binary indexed tensors.
[30]:
from binascii import hexlify
import numpy as np
def to_hex_str(binary_vector):
return str(hexlify(np.array(binary_vector, dtype=np.int8)), "utf-8")
Feed using hex format
[32]:
with app.syncio() as sync:
for i, doc in enumerate(documents):
response: VespaResponse = sync.feed_data_point(
schema="doc",
data_id=str(i),
fields={
"doc_id": str(i),
"text": doc,
"binary_vector": {
"values": to_hex_str(cohere_response.embeddings.binary[i])
},
},
)
assert response.is_successful()
Querying data
Read more about querying Vespa in:
[33]:
query = "Who discovered x-ray?"
# Make sure to set input_type="search_query" when getting the embeddings for the query.
# We ask for both float and binary query embeddings
cohere_query_response = co.embed(
[query],
model="embed-english-v3.0",
input_type="search_query",
embedding_types=["float", "binary"],
)
Now, we use nearestNeighbor search to retrieve 100 hits using hamming distance, these hits are then exposed to vespa ranking framework, where we re-rank using the dot product between the float tensor and the unpacked binary vector (the unpack returns a 1024 float version).
[35]:
response = app.query(
yql="select * from doc where {targetHits:100}nearestNeighbor(binary_vector,q_binary)",
ranking="rerank",
body={
"input.query(q_binary)": to_hex_str(cohere_query_response.embeddings.binary[0]),
"input.query(q_full)": cohere_query_response.embeddings.float[0],
},
)
assert response.is_successful()
[36]:
response.hits
[36]:
[{'id': 'id:doc:doc::3',
'relevance': 8.697503089904785,
'source': 'cohere_content',
'fields': {'matchfeatures': {'closeness(field,binary_vector)': 0.0029940119760479044,
'distance(field,binary_vector)': 333.0},
'sddocname': 'doc',
'documentid': 'id:doc:doc::3',
'doc_id': '3',
'text': 'Marie Curie was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity'}},
{'id': 'id:doc:doc::1',
'relevance': 6.413589954376221,
'source': 'cohere_content',
'fields': {'matchfeatures': {'closeness(field,binary_vector)': 0.002551020408163265,
'distance(field,binary_vector)': 391.00000000000006},
'sddocname': 'doc',
'documentid': 'id:doc:doc::1',
'doc_id': '1',
'text': 'Albert Einstein was a German-born theoretical physicist who is widely held to be one of the greatest and most influential scientists of all time.'}},
{'id': 'id:doc:doc::2',
'relevance': 6.379772663116455,
'source': 'cohere_content',
'fields': {'matchfeatures': {'closeness(field,binary_vector)': 0.002652519893899204,
'distance(field,binary_vector)': 376.0},
'sddocname': 'doc',
'documentid': 'id:doc:doc::2',
'doc_id': '2',
'text': 'Isaac Newton was an English polymath active as a mathematician, physicist, astronomer, alchemist, theologian, and author who was described in his time as a natural philosopher.'}},
{'id': 'id:doc:doc::0',
'relevance': 4.5963287353515625,
'source': 'cohere_content',
'fields': {'matchfeatures': {'closeness(field,binary_vector)': 0.0024271844660194173,
'distance(field,binary_vector)': 411.00000000000006},
'sddocname': 'doc',
'documentid': 'id:doc:doc::0',
'doc_id': '0',
'text': 'Alan Turing was an English mathematician, computer scientist, logician, cryptanalyst, philosopher and theoretical biologist.'}}]
Notice the returned hits. The relevance is the score assigned by the second-phase dot product between the full query version and the unpacked binary vector. Also, we see the match features and the hamming distances. Notice that the re-ranking step has re-ordered doc 1 and doc 2.
Conclusions
These new Cohere binary embeddings are a huge step forward for cost-efficient vector search at scale and integrates perfectly with the rich feature set in Vespa.
Clean up
We can now delete the cloud instance:
[ ]:
vespa_cloud.delete()